What does Mark Twain Talk About?
Overview
This webpage details the work that I did as part
of my midterm for the Hacking the Humanities course
at Carleton in Fall Term of 2022. For the project, I analyzed
a dataset containing speeches given by Mark Twain. I performed
textual analysis on this data to extrapolate some of the topics
that Mark Twain talks about in his speeches. The following
sections detail more about the outcomes and process involved.
Sources
For this project, I used a dataset containing speeches of Mark Twain. While I got this dataset from
a folder shared by the class, the data actually came from Project Gutenberg. A link to the original
data on the Project Gutenberg website can be found
here
Process
Once I obtained the data, I began some preliminary exploration of it
using Voyant Tools. By using Voyant Tools, I could get a sense of some
of the most frequently used words amongst all of Mark Twain's speeches.
Voyant Tools has the added benefit of automatically detecting stopwords
for you (e.g. 'the', 'and', 'that', 'a'). An embedding of Voyant Tools output is
attached below:
However, I wasn't content with how effective Voyant was in figuring out the topics that
Mark Twain would talk about in his speeches. I also felt that I need to dive deeper into
the process of data cleaning to get better results. As such, I moved towards Python and
Natural Language Understanding techniques. In this case, emphasizing topic modeling
using a technique called Latent Dirichlet Allocation (LDA). There are many explanations
of LDA on the web, and many resources that show how it can be done in Python (all of which I used
as LDA is quite novel to me as well). In particular, I found this resource useful
for understanding LDA and this resource useful for learning how to implement
it using Python code.
I had to do a lot of preprocessing before I could use the data with LDA models and get somewhat coherent topics.
This preprocessing involved a lot of things within the field of natural language processing (NLP) such as tokenization,
lemmatization, and other more familiar things like removing stopwords. After cleaning the data, I used a Python library called
gensim to do the topic modeling. Here is a picture of some of the results I got from doing this topic modeling. Specifically,
what the results show is 4 potential abstract topics from the text, and it is our job to place labels on these abstract topics.
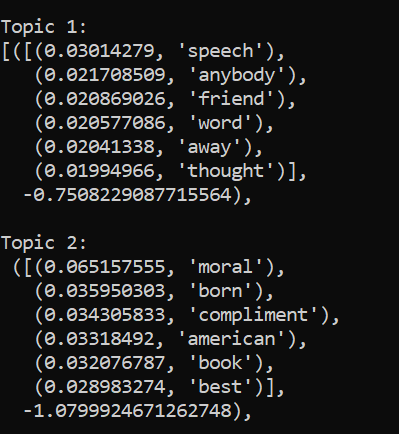
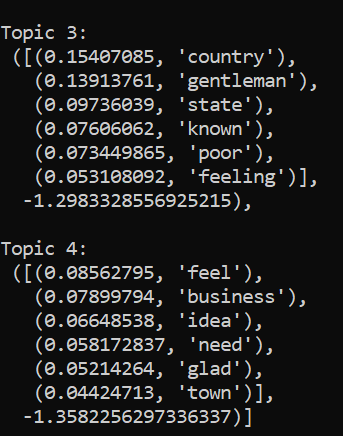
Further discussion of these results and other images depicting the process and outcomes can be found upon clicking the 'Images' tab.
Presentation
In regards to the presentation of my project (which is exactly what is seen on this website),
I decided to built a site completely from scratch using HTML and CSS. Doing so allows me a
lot of flexibility with what I can do and I found it to be a great excercise of my competency
in web technologies.
Significance
Using topic modeling on the speeches of Mark Twain, I was able to better understand the topics that
Mark Twain would talk about in his speeches. Specific topics I converged upon were 'speech-related', 'business',
'contemporary america', 'and 'nationalism'.